
AI-generated answers feel instant and authoritative, but each one is built through a layered internal process. The model has to decide what it knows, what it can fetch, what to trust, and how to phrase it. That stack of decisions is what we mean by the anatomy of an AI-generated answer.
Understanding this anatomy is essential if you want to influence how your brand appears or doesn’t in AI responses. Because LLM visibility isn’t just about being online anymore; it’s about being processed correctly.
In this guide, we’ll break down each part of that anatomy and what it means for you.
TL;DR
- AI-generated answers are not retrieved; they’re constructed through a layered process: training memory, retrieval, filtering, and generation.
- Models don’t “look up” your brand by default; they either learn it during training or retrieve it in real time.
- Visibility depends on strong signals: third-party presence, specific information, and consistent messaging across sources.
- AI citations only show a portion of what influenced the answer, making inclusion more important than ranking.
- Hallucinations occur when models lack reliable data, leading to missing, incorrect, or fabricated brand information.
1. The Brain – What the Model Actually Is
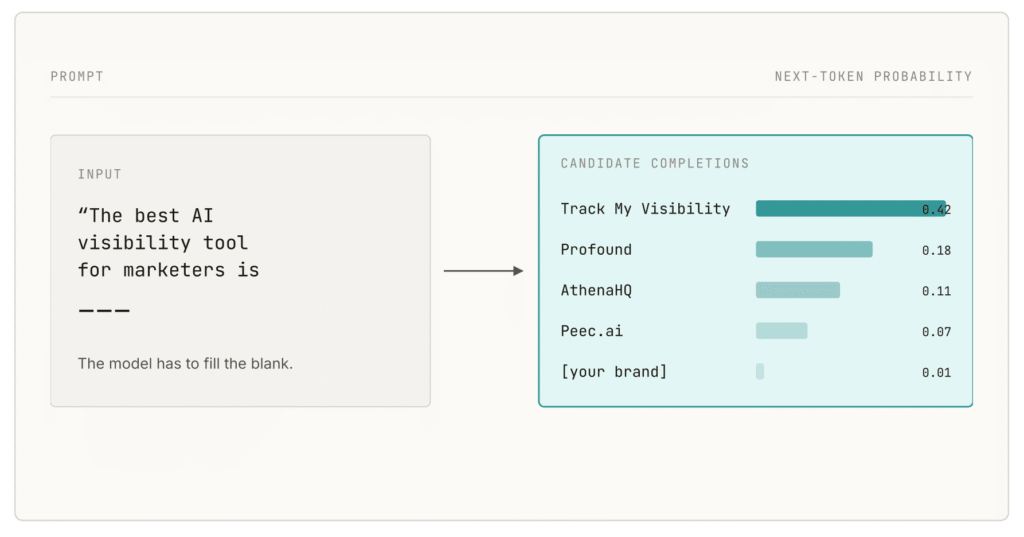
At its core, an AI model is not a search engine or a live database; it’s a pattern-completion system. It doesn’t “look up” answers in real time by default. Instead, it generates the most probable response based on patterns it learned during training. Every AI-generated answer is essentially a prediction of what should come next, given the input and its prior knowledge.
This has a direct implication. The model doesn’t actively go searching for your brand unless retrieval is involved. It either already “knows” your brand from its training data, or it doesn’t exist in its internal representation. That means visibility starts long before the prompt is ever typed.
2. The Memory – Where It Learned What It Knows
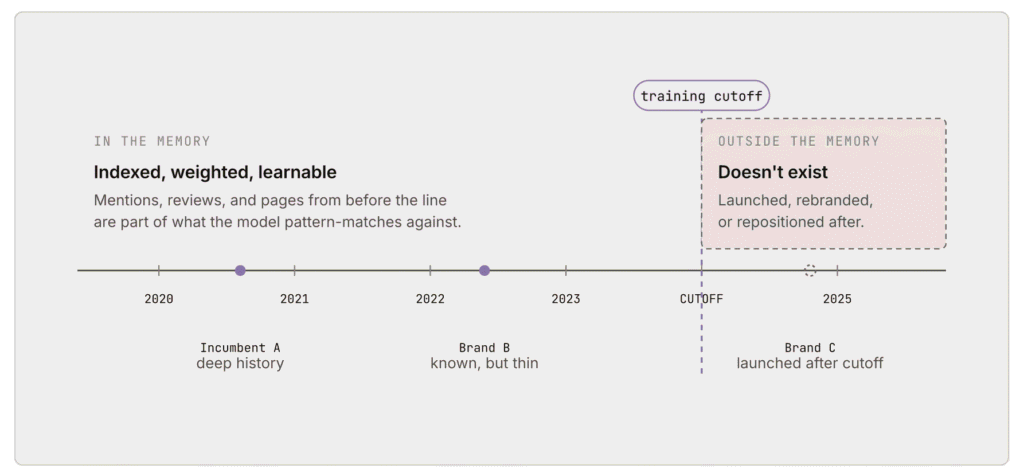
The idea of “memory” in Artificial Intelligence comes from how models are trained, not from storing facts like a database, but from encoding patterns into parameters. During training, the AI model processes massive amounts of text and learns statistical relationships between words, concepts, and entities. What we call “memory” is actually this compressed representation of knowledge inside the model’s weights, not something it can browse or update on demand.
This memory is built from a large snapshot of data collected before the model is released. Models like ChatGPT, Claude, and Perplexity each rely on such training phases, which introduce a knowledge cutoff, a point after which new information isn’t inherently known. For example, if a brand gained traction after that cutoff, the model may have little to no awareness of it.
So brands with a strong, consistent presence across the web before the cutoff are more likely to be recognized. The ones without that footprint face a visibility gap. Not because they aren’t relevant, but because they weren’t well represented in what the model learned.
 Pro Tip: Want to know where your brand stands across AI platforms? Run a quick audit to check your AI visibility and see how your brand currently shows up across major AI platforms.
Pro Tip: Want to know where your brand stands across AI platforms? Run a quick audit to check your AI visibility and see how your brand currently shows up across major AI platforms.3. The Eyes – How Some Models Read The Web In Real Time
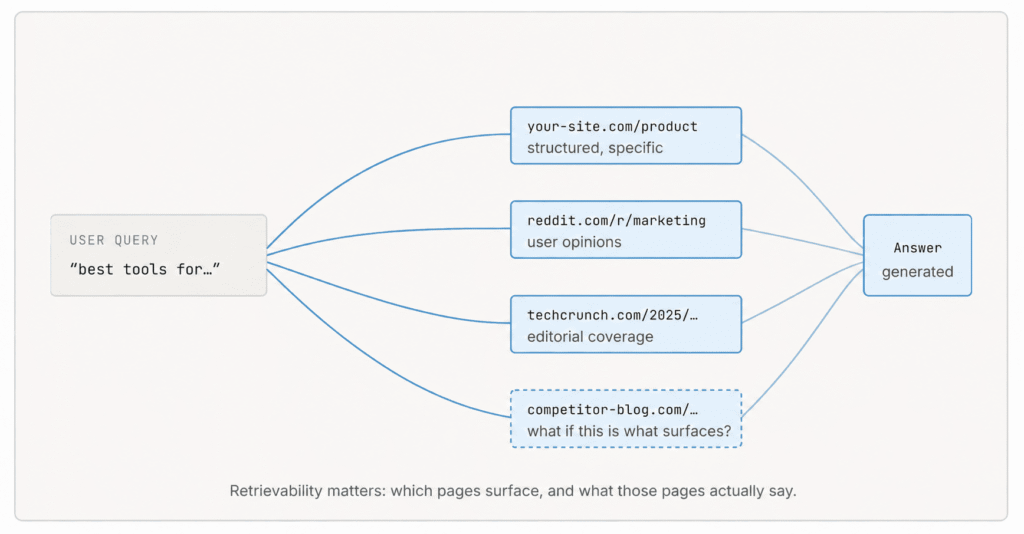
Some AI systems don’t rely only on training. They access and process information from the web at the moment of the query. That ability lets them “see” fresh content and shapes the AI-generated answer in real time.
→ RAG: How Models Access Live Web Data
Some AI systems extend beyond static training by using Retrieval-Augmented Generation (RAG). Models like ChatGPT (with browsing), Claude, Google Gemini, and Perplexity first retrieve relevant web pages from the internet for a query, then use that content as context to generate an answer.
Research on retrieval-based systems, including the original RAG paper by Lewis et al. (2020), shows that the top few results, often just 3 to 5 documents, supply most of the context used in the final answer. Anything outside that set is effectively ignored.
So the model doesn’t lean only on what it learned during training. It reads selected pages live, interprets them, and produces a synthesized AI-generated response. Ask about a recent product launch, and the system may pull current articles or blog posts, process them, and generate an answer grounded in those sources.
→ Visibility: What the Model Can Actually See
This changes how visibility works. It’s no longer just about being part of the model’s training memory. It’s about being retrievable when the query happens.
Which pages surface for relevant prompts? How clearly do they describe your brand? If your content isn’t easily discoverable or structured in a way the model can interpret, it may be skipped or misread. In real-time systems, visibility depends on both access and clarity of what the model can find, and how well it can process it.
4. The Filter – How It Decides What’s Worth Including
After gathering information from training memory or real-time retrieval, the AI model doesn’t use everything it sees. It applies internal filters to determine what is most relevant, reliable, and worth including in the final answer. This step is critical because it shapes not just what appears, but also what gets ignored.
The filtering isn’t rule-based. It’s driven by learned patterns about what “good” information looks like. As a user described in this Reddit thread, content that is clear, repeated, and consistent is more likely to be included, while vague or conflicting information is often dropped or softened.

Key Filters AI Models Apply
- Relevance: How closely the content matches the query intent
- Repetition: Information mentioned consistently across multiple sources
- Specificity: Concrete details, data points, and clear claims
- Authority signals: Indicators of credibility (well-structured, informative content)
- Consistency: Alignment across sources vs conflicting information
- Clarity: Easy-to-interpret language over ambiguous or abstract wording
- Context fit: Whether the information logically fits within the generated response
5. The Mouth – How It Turns All Of That Into A Confident Answer
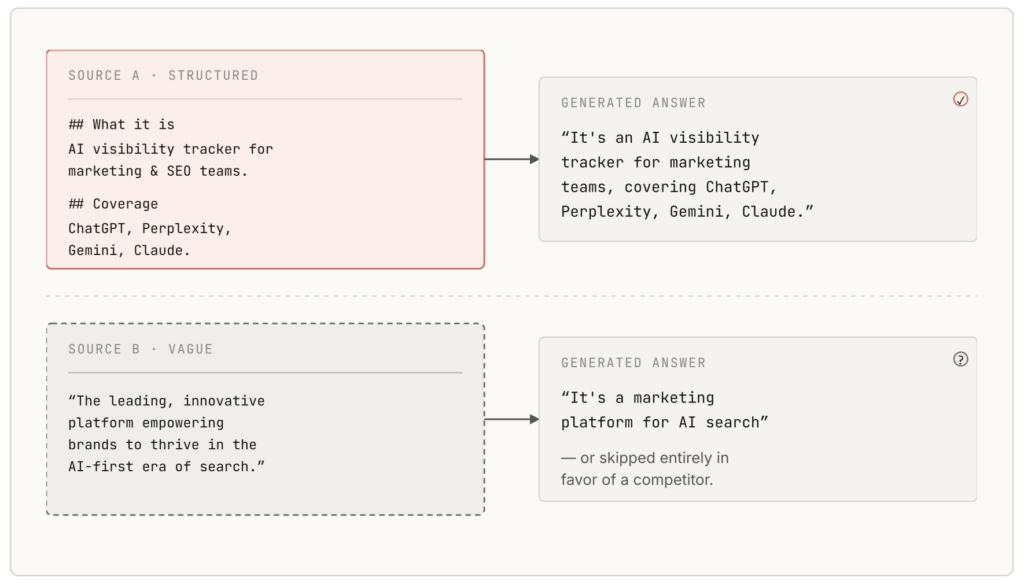
After selecting what to include, the model generates a final answer by combining and rewriting information into a single, coherent response. It doesn’t copy sources. It predicts the most likely phrasing based on context and learned patterns. How that output is perceived depends largely on citations and the tone of different AI platforms.
At this stage, two things define how the answer is perceived: how citations are presented and how confidently the response is delivered.
→ AI Citations: What They Are and How They Appear
AI citations are references to the sources that influenced the answer. They show up in different ways depending on the system:
- Explicit citations: Visible links or references (common in Google AI overviews and tools like Perplexity)
- Implicit citations: No visible links, but the answer is still shaped by underlying top sources
Importantly, LLM citations are selective. They don’t represent everything the model used, only a subset deemed most relevant or useful to display. This means an answer may be influenced by multiple sources, even if only a few are cited.
Pro Tip: Most brands assume they are being cited because their content ranks. The AEO GEO audit checklist breaks down exactly what AI systems look for when deciding what to cite.→ How AI Generates Confident Answers
AI tools are optimized to produce fluent, coherent language, which naturally makes responses sound clear and authoritative. In this process, LLMs choose content based on patterns learned during training and the context available at runtime, rather than actively evaluating truth. They predict the most likely sequence of words that fits the input.
Because this process prioritizes readability over verification, the model rarely signals uncertainty unless explicitly prompted. Even when information is incomplete or weakly supported, the final answer can still come across as confident and definitive.
6. The Blind Spots – Where Brands Fall Through The Cracks

Even when content exists, that alone doesn’t guarantee inclusion in AI-generated answers. Gaps in training data, weak retrieval signals, or unclear positioning can leave brands overlooked or, worse, misrepresented. This is where hallucinations enter the picture.
Hallucinations happen when an AI model generates information that isn’t grounded in reliable sources or verifiable data. Instead of retrieving a fact, the model fills the gap using pattern prediction, which can produce fabricated details, incorrect associations, or missing context.
This usually happens when the model lacks strong or consistent signals about a topic, encounters conflicting information, or is pushed to give specific answers without enough supporting data.
For brands, the impact is real. You may not appear at all, or you may appear inaccurately. Either way, the issue goes beyond correctness. This is where brand mention matters, because it directly affects visibility, trust, and how your brand is understood inside AI-generated responses.
7. What You Can Control – How To Feed The Anatomy Better

You can’t control how AI models are trained or how they generate answers. You can influence what they learn, retrieve, and include. Optimizing for AI answers means aligning your content with how these systems process information, so it’s easier to find, interpret, and trust.
Build Brand Presence Across Third-Party Sources
AI platforms don’t rely on a single source. They look for patterns across the web. Platforms like Perplexity and retrieval-enabled models such as ChatGPT often surface information from multiple domains before generating a response. If your brand only exists on your own site, it’s a weak signal.
Expand your footprint through customer reviews, editorial mentions, directories, social media, and industry publications. Being mentioned consistently across blogs, Wikipedia, and review platforms increases the likelihood that your brand is both retrieved and trusted.
Pro tip: So what actually pushes one brand into AI answers while another stays absent? The factors behind frequent mentions are more controllable than they look. How to appear in AI search results breaks down what drives that visibility.Use Specific, Verifiable Information in Content
AI models favor content that is concrete and precise. Vague claims like “best solution” or “leading platform” are often ignored or generalized. Instead, include verifiable details, pricing ranges, feature comparisons, use cases, and measurable outcomes.
For instance, instead of saying “fast performance,” say “reduce page load time by 40%.” This level of detail makes it easier for AI systems to extract and confidently include your brand in answers, especially when generating comparisons or recommendations.
Maintain Consistent Brand Information Across Channels
Consistency acts as a trust signal. If your brand is described differently across your website, PR articles, and listings, machine learning models may struggle to form a clear understanding or may omit you entirely.
Keep your core messaging, product positioning, and key facts aligned across every channel. If one page calls you a “marketing analytics tool” and another calls you an “AI visibility platform,” the inconsistency dilutes your presence in AI-generated responses.
Structure Content for AI Readability and Extraction
AI models don’t read like humans. They parse the structure. Clear headings, concise sections, and direct answers improve how your content gets interpreted. Well-organized pages are more likely to be retrieved and accurately summarized.
Pages built with FAQs, bullet points, and well-defined sections perform better in systems like Perplexity and ChatGPT because the model can quickly identify and extract the relevant information for a given query.
How to Know Where You Stand in AI Answers?
One of the biggest challenges for brands today isn’t just visibility; it’s uncertainty. This is where tracking AI search visibility becomes critical. You don’t know if your brand is being included in AI-generated answers, how often it’s cited, or whether it’s being misrepresented. Unlike traditional search, there’s no clear ranking page to analyze. You’re either inside the answer or invisible to it.

This is where Track My Visibility comes in. Track My Visibility is an AI visibility tracking platform designed to help brands understand how they appear across AI systems. By running prompt-based queries across models, it shows where your brand is mentioned, cited, or missing entirely, giving you a clear view of your presence inside AI-generated responses.
Think of it as the starting point for everything the anatomy points to.
- Before you can build breadth, you need to know how thin your current footprint is.
- Before you can fix consistency, you need to see where the contradictions are showing up.
- Before you can optimize for retrieval, you need to know whether you’re being retrieved at all.
If you’re serious about understanding and improving your visibility in AI answers, exploring how your brand currently performs is the first step. Start with a 7-day free trial and see exactly where you stand.
FAQs
An AI-generated answer is a response created by a language model that synthesizes information from its training data and, in some cases, real-time sources. Instead of listing links, it delivers a direct, structured answer based on patterns, context, and available inputs.
AI models use a combination of learned patterns and retrieval signals to decide what to include. They prioritize content that is relevant, repeated across multiple sources, specific, and consistent. Information that lacks clarity or strong signals is often ignored.
Hallucinations occur when the model generates information without a strong or reliable source backing. This happens due to gaps in training data, weak retrieval results, or the model’s tendency to predict likely answers rather than verify facts.
Brands can improve visibility by building a strong presence across third-party sources, using clear and verifiable information, maintaining consistency across channels, and structuring content in a way that AI systems can easily interpret and extract.
Tracking AI visibility requires analyzing how your brand appears across different prompts and platforms. Tools like Track My Visibility help brands monitor mentions, citations, and presence in AI-generated responses, making it easier to identify gaps and improve inclusion.
Reference
1. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks – Lewis et al., 2020.





