Most content teams treat freshness and depth as competing priorities, publish fast or go deep, as if the choice is binary. But Large Language Models do not operate that way.
AI citation systems evaluate multiple signals simultaneously. Content freshness indicates whether content meets recency needs. Depth determines whether it offers enough coverage and specificity for extraction. Neither signal works in isolation. For time-sensitive queries, recency can dominate. For complex or explanatory queries, depth carries more weight.
The real variable is context: query intent, platform behavior, and timing all influence how these signals are prioritized. This is why newer content doesn’t automatically win LLM citations. What matters is how effectively a piece balances freshness and depth to deliver a complete, reliable answer.
This article breaks down what LLMs prefer when citing content and what that means for building citation-worthy content.
TL;DR
- LLMs don’t choose between freshness and depth; they weigh both based on query intent and context
- Freshness dominates in time-sensitive queries (pricing, tools, regulations, finance) where outdated data risks accuracy
- Depth drives citations for complex queries by enabling complete, multi-step answers through strong coverage
- Citation decisions happen at the passage level, making content structure and extractability critical
- Winning strategy: build comprehensive content and maintain it with consistent, meaningful updates
How LLMs Evaluate Content Before Citing It
Before freshness or depth comes into play, AI determines whether a piece is even eligible for citation. This happens through a retrieval pipeline that operates at a much more granular level than traditional search. Instead of evaluating entire web pages, AI systems break a query into smaller sub-queries, each representing a specific intent or information need.
AI systems process content as chunks or relevant passages rather than full articles. AI citation decisions are made at this passage level, which means a single well-structured section can be selected even if the rest of the page is less relevant. What matters here is semantic alignment, how closely a passage matches the intent behind the user queries.
Only after this initial filtering do other signals come into play. Brand authority, entity clarity, and structural organization help determine which passages are reliable and extractable enough to surface. In this system, clarity and relevance at the micro level often matter more than the overall strength of the page.
Why Content Freshness Is a Measurable LLM Citation Factor
Content freshness is a quantifiable citation signal in LLM visibility, used to ensure outputs reflect up-to-date information. During retrieval, AI models prioritize sources aligned with the latest available data, especially for queries tied to change over time. This makes freshness a core component of LLM citation factors.
Freshness is evaluated through clear relevance signals: visible publish or “last updated” dates, structured metadata such as dateModified, and alignment between timestamps and actual content updates. AI systems also compare multiple sources to identify which reflects the most recent consensus.
Its influence depends on the query type. For topics like tools, pricing, regulations, or trends, recency strongly affects AI source selection. In these cases, outdated content is less likely to be cited, regardless of overall quality.
How Freshness Weight Varies by Platform

Freshness vs depth in LLM citations plays out differently depending on which AI platform is doing the retrieving. Here’s what this looks like for each major platform.
ChatGPT citations show a strong preference for recent content, with a meaningful share coming from pages updated within the past 90 days. It often surfaces sources that are significantly fresher than traditional search results, especially for evolving topics. Research suggests content updated within 90 days sees roughly 98% higher citation rates compared to content last updated over a year ago.
Perplexity searches lean most heavily on real-time retrieval. It has the strongest recency bias of the major platforms, a substantial portion of citations comes from current-year content, and content updated within 30 days can see citation rates jump as much as 142% compared to older content. For time-dependent queries, Perplexity is the most sensitive platform to freshness signals.
Google AI Overviews apply a more conservative approach, favoring established relevance alongside acceptable recency. The freshness advantage is real but less aggressive than Perplexity or ChatGPT.
 Pro Tip: Want to know where your brand stands across AI platforms? Run a quick audit with a free AI visibility checker and see how your content currently performs across AI search platforms.
Pro Tip: Want to know where your brand stands across AI platforms? Run a quick audit with a free AI visibility checker and see how your content currently performs across AI search platforms.Why Content Depth Drives LLM Citations on Complex Queries
For complex queries, language models prioritize content that can fully resolve multiple layers of intent. These queries often include “how,” “why,” or “compare” structures, where a single surface-level answer is insufficient. In such cases, depth becomes a critical LLM citation factor because it determines whether a source can support multi-step reasoning.
Depth isn’t defined by length, but by completeness. Content with strong entity coverage, clear relationships, and specific claims is more likely to match multiple sub-queries within a single prompt. This increases its chances of being selected across different parts of the AI-generated response. As a result, even older content can appear in AI search if it remains structurally comprehensive and contextually accurate.
Unlike freshness, which helps content qualify for time-sensitive queries, depth allows content to persist and compound in AI visibility across repeated use cases. For complex topics, LLMs favor authoritative sources that reduce the need to stitch together multiple shallow passages.
What Depth Looks Like Inside a Retrieval System
From a retrieval perspective, depth is reflected in how easily content can be extracted and reused at the passage level. AI models don’t interpret an article as a whole. They identify specific sections that directly answer parts of a query.
This means high-performing content is structured into self-contained blocks, where each section addresses a distinct sub-topic clearly and completely. Clear heading hierarchy (H2–H4), precise language, and explicit entity references improve semantic matching and citation accuracy.
A short, well-defined passage that directly answers a sub-question is more valuable than a long, unstructured explanation. Clarity, specificity, and modular content structure make content more “retrieval-friendly,” increasing citation probability.
Query Types Where Freshness Outweighs Depth
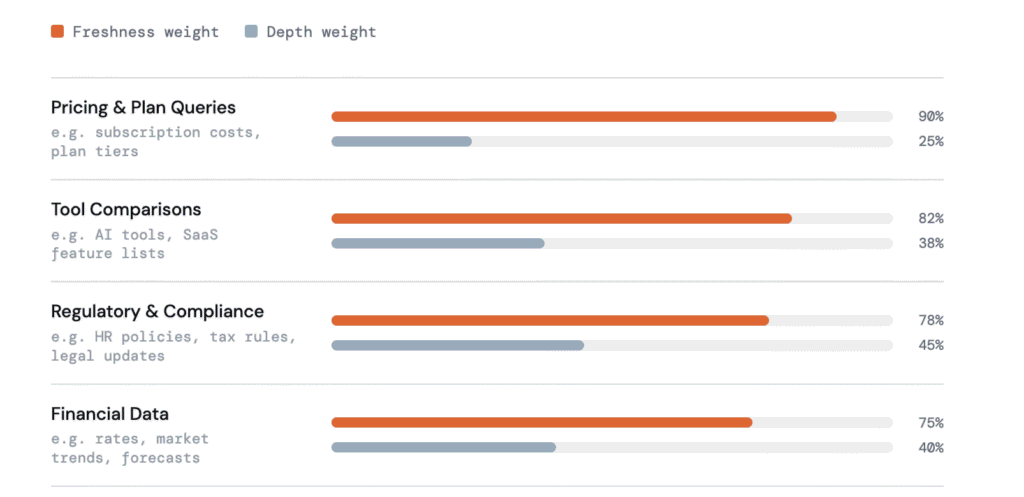
Freshness dominates in queries where accuracy depends on up-to-date information and where outdated data increases the risk of incorrect answers. These are typically high-change, decision-oriented queries.
Pricing queries (subscription costs, plan tiers) show strong recency sensitivity, as even minor changes can invalidate older content. Tool comparisons, especially in fast-moving categories like AI or SaaS, favor recently updated lists that reflect current features and market shifts.
Regulatory and compliance queries (HR policies, legal updates, tax rules) also require current information, where outdated guidance can lead to serious errors. Financial data queries, including rates, market trends, or forecasts, follow similar patterns.
Industry context amplifies this effect. Finance, HR compliance, and travel consistently show the strongest freshness bias in citation patterns. In these areas, content older than 12 months often falls outside citation consideration, regardless of depth.
Query Types Where Depth Outweighs Freshness
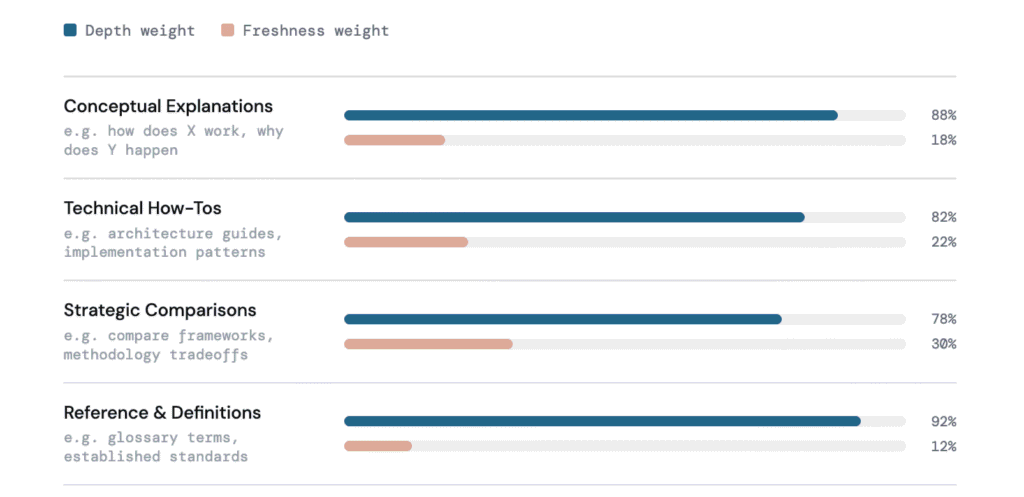
Depth becomes the primary signal in queries focused on understanding rather than immediacy. Stable conceptual, technical, and strategic queries often framed as “how,” “why,” or “compare” favor comprehensive coverage over publication date, as the underlying information does not change frequently.
When recency signals are similar across sources, authority proxies such as brand strength and domain age influence which content is selected. Well-established domains are more likely to be trusted when the depth and relevance of information are comparable.
There’s also a compounding advantage. Content that achieves early, deep coverage tends to be reused across multiple user queries, strengthening its position in citation frequency over time. This makes it difficult for newer, thinner content to displace it. Established reference sources like Wikipedia continue to earn citations despite their age because their coverage remains comprehensive and consistently relevant.
Pro Tip: Depth alone does not protect against the citation logic AI systems apply when evaluating sources, and the gap between ranking well and being cited is where visibility quietly disappears. The AEO GEO Audit Checklist breaks down exactly what AI systems look for when deciding what to cite.How to Optimize Content for Both Freshness and Depth
Optimizing content for freshness and depth requires treating them as complementary layers, not separate strategies. Depth builds long-term relevance by fully covering a topic, while freshness keeps that coverage accurate and competitive. The objective is to create content that remains eligible for citation over time by being both comprehensive enough to answer complex queries and updated enough to stay trustworthy in fast-changing contexts.
- Build pillar pages with full coverage: Cover core topic, subtopics, and related entities so one page can satisfy multiple query variations and reduce reliance on fragmented sources.
- Structure content into modular sections: Use self-contained sections that answer specific sub-questions, improving passage-level extraction and increasing citation chances.
- Update content incrementally, not entirely: Add new data, sections, or examples instead of rewriting; preserves authority while improving freshness signals efficiently.
- Refresh time-sensitive sections more frequently: Regularly update pricing, stats, tools, and trends so critical parts remain eligible for recency-sensitive queries.
- Maintain clear heading hierarchy (H2–H4): Helps AI crawlers understand structure, improves semantic matching, and ensures sections align with specific query intents.
- Expand coverage as new query patterns emerge: Add sections for new use cases or comparisons to increase topical depth and capture evolving search demand.
- Align visible update signals with real changes: Ensure “last updated” dates reflect actual improvements, reinforcing trust and preventing deprioritization by AI engines.
- Improve entity clarity and specificity: Use precise terms, defined concepts, and clear relationships to strengthen semantic relevance and retrieval accuracy.
Refresh vs Rebuild: Choosing the Right Update Strategy
Not all content should be updated the same way. The decision to refresh or rebuild depends on why a page is underperforming or lacks depth. AI systems do not respond to superficial edits like swapping years or minor rewording, as these don’t change the underlying information value. Meaningful re-evaluation happens only when the content itself improves.
A refresh is appropriate when a page already has strong coverage but has lost visibility due to outdated information. In this case, the structure and depth are intact, but key details need updating. A substantive refresh includes adding new entities, updating statistics, expanding sections, or correcting outdated claims. This helps the page regain relevance without losing its existing authority.
A rebuild is necessary when the page lacks depth from the start. If content was never earning citations, updating the date or making minor edits will not improve performance. These pages require expanded coverage, better structure, and stronger entity-level clarity to become eligible for citation.
In short, refresh content that is aging but still strong. Rebuild content that was never competitive.
| Refresh when | Rebuild when |
| The page was earning citations, but dropped in the last 6 months | The page never earned citations despite being indexed |
| Core coverage is strong; stats, examples, or tools are outdated | Entity coverage is thin vs top-cited competitors |
| dateModified hasn’t been updated in 90+ days on time-sensitive topics | Headings don’t align with sub-queries or user intent |
| Competitors published fresher versions and replaced your citations | Content is keyword-driven, not passage-level extractable |
| Structure is intact and still maps well to query intent | The existing structure can’t be improved with incremental edits |
Auditing Your Content Against Both LLM Citation Factors
Freshness and depth of content are not competing signals; they work together to determine whether your content gets cited or ignored. Content that is comprehensive but outdated gradually loses AI visibility, while fresh but shallow content fails to sustain citations. The advantage comes from maintaining both.
That makes AI search auditing essential. Without a clear way to measure AI visibility across these dimensions, it’s difficult to know whether to refresh, expand, or rebuild your content.

This is where Track My Visibility becomes useful. It helps you understand how your content is actually performing inside AI answers, not just traditional search. You can track whether your pages are being cited, identify drops in citation share, and see which competitors are replacing you. It also surfaces gaps in coverage and freshness, highlighting pages that need updates versus those that require deeper restructuring.
Instead of guessing, you get a clear view of where you stand across AI platforms and what actions will improve your visibility.
If you want to see how your content performs in real AI citation environments, you can try it with a 7-day free trial.
FAQs
LLMs don’t universally prefer one over the other. Freshness matters more for time-sensitive queries, while depth is prioritized for complex or explanatory queries. The weighting depends on query intent and platform behavior.
Key factors include semantic relevance, passage-level clarity, entity coverage, content structure, freshness signals, and overall depth. These signals work together during retrieval and selection.
AI systems break queries into sub-parts, retrieve relevant passages (not full pages), and select content based on how well it matches intent, clarity, and reliability signals like freshness and depth.
Traditional SEO tools don’t show AI citation visibility. Platforms like Track My Visibility help track whether your content appears in AI-generated answers, identify citation drops, and analyze which competitors are replacing you across different query types.
Yes, if it remains comprehensive, accurate, and well-structured. Deep content with strong coverage can continue earning citations even if it’s not recently updated, especially for stable topics.
References
1. How Does Google AI Overview Work? Insights From the Patent
2. ChatGPT Citations: 44% Come From the First Third of Content According to Landmark Study
3. How to Rank Higher on Perplexity: Expert Search Tips That Actually Work





